Crafting Interpreters: Reading Note
My reading note of the book Crafting Interpreters.
The book will use Java and C, so need to setup them and brush up a bit.
Chapter 2: A Map of the Territory
The Parts of a Language
Language implementation can use a metaphor like climbing mountain:
- From low level source code, we analyze the program and transform it to higher-level representation where the semantics become more apparent.
- Reaching the highest level, where we can see what the code means, we start descent down the mountain by transforming this highest-level representation down to lower-level form to get closer to something we know how to make the CPU actually execute.
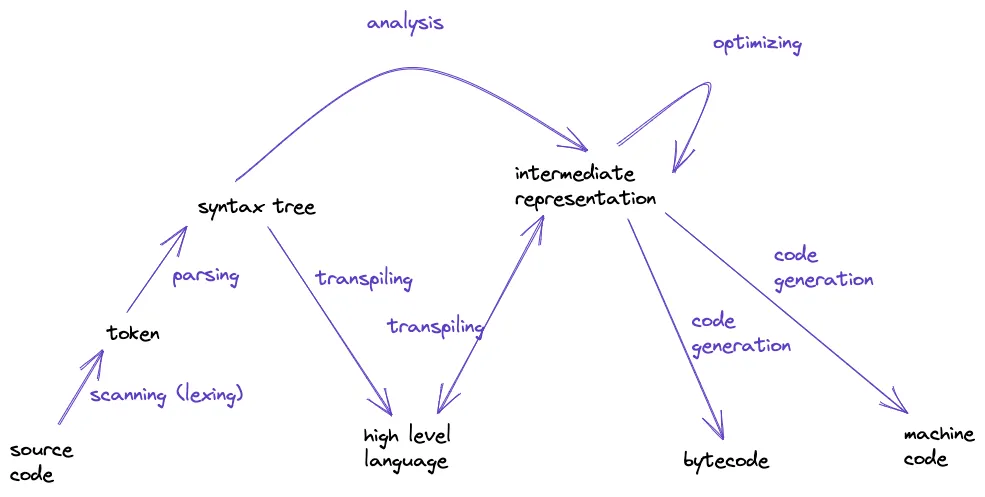
Scanning
Scanning, also known as lexing and lexical analysis, is the process of transforming characters and chunks them into a series of something like “words”. In programming languages, each of these words are known as a token.
Parsing
This is where our syntax gets a grammar - the ability to compose larger expressions and statements out of smaller parts. This is like in English grammar class where English teacher explains about Subject, Predicate, Verb, Object etc.
A parser takes the flat sequence of tokens and build a tree structure that mirror the nested nature of the grammar. These trees have different names - parse tree, abstract syntax tree, syntax trees, ASTs, or often just trees.
Parser’s job also includes letting us know when we make grammar mistakes by reporting syntax errors.
Static Analysis
This stage is where implementation starts getting very different for each programming language.
For example, in an expression of a + b, we know we are adding a and b, but we don’t know what those names refer to. Are they local variables? Global? Where are they defined?
The first bit of analysis that most languages do is called binding or resolution. For each identifier, we find out where the name is defined and wire the two together. This is where scope comes into play.
If the language is statically typed, this is when we type check. Once we know where a and b are defined, we also figure out their types and check if the a + b operation is supported for their types. If not, we report a type error.
The result of static analysis can be stored in a few formats:
- stored back to the syntax tree itself as attributes.
- stored in a separate lookup table, usually known as symbol table.
- transform the tree into a new data structure.
Intermediate representations (IR)
We can think of the compiler as a pipeline where each stage’s job is to organize the data representing the user’s code in a way that makes the next stage simpler to implement. The “frontend” of this pipeline is the source language the user writes, the “backend” is the final architecture where the program will run, and in the middle, intermediate representations.
Optimization
Once we understand what the user’s program means, we are free to swap it out with a different program that has the same semantics but implements them more efficiently - we optimize it.
Code generation
The last step is convert the program to a form that machine can actually run. This process is known as code generation or (code gen), where “code” here refers to the primitive assembly-like instructions a CPU runs.
We can choose to generates instructions for a real CPU (native) or to a hypothetical, idealized machine (virtual). Native code is lightning fast, but generating it takes a lot processing and it is not portable. Meanwhile, generating code that works for virtual machine is usually faster and much more portable, but it requires running a virtual machine. This type of code intended to be run with virtual machine is known as bytecode.
Virtual machine
With bytecode, there are additional steps required, with two approaches:
-
pass through bytecode to another compiler for each target architecture that converts bytecode to native code for that machine. In other words, the bytecode is functionally a intermediate representation.
-
write a virtual machine (VM), a program that emulates a hypothetical chip supporting the virtual architecture at runtime. Running bytecode in a VM is slower than translating it to native code ahead of time, but we get simplicity and portability.
Runtime
Running our code depends on how we compiled it. If we compiled our code to machine code, then we simply tell the OS to load the executable. If we compiled it to bytecode, we need to start up the VM and load the program into that.
Regardless, we usually need some services that our language provides while the program is running, such as garbage collection, “instance of” checks, and so on. These are collectively known as the runtime.
In a fully compiled language, the code implementing the runtime get inserted directly into the executable. In a VM-based language, the runtime is lives in the VM.
Compilers and Interpreters
-
Compiling is an implementation technique that involves translating a source language to another - usually lower-level - form.
-
A compiler translates source code to some other form but doesn’t execute it.
-
An interpreter takes in source code and executes it immediately.
An interpreter can includes a compiler as part of its implementation - when it receives a program, it compiles it to some lower-level form and then immediately executes it.
TO BE CONTINUED…